
Harvard Library
AI Cataloger
Build an GEN-AI powered workflow to generate book subject headings for library catalogers using LLM and Retrieval Augmented Generation, result in a 2.62% time consumption.
Role
AI Engineer
Product Lead
Tools
LLM
RAG (Langchain)
React
Timeline
Apr 2023 - Present
Library & Data & AI
The task of a cataloger heavily relies on knowledge and experience, which are strengths of current LLMs. Cataloging is also an iterative process that doesn’t aim for high accuracy on the first try. These features make it intuitive to involve more AI-related investigations in the current library system. It’s about data. It’s about text. LLMs are efficient, multilingual, and scalable. How can Generative-AI technology help streamline library work?

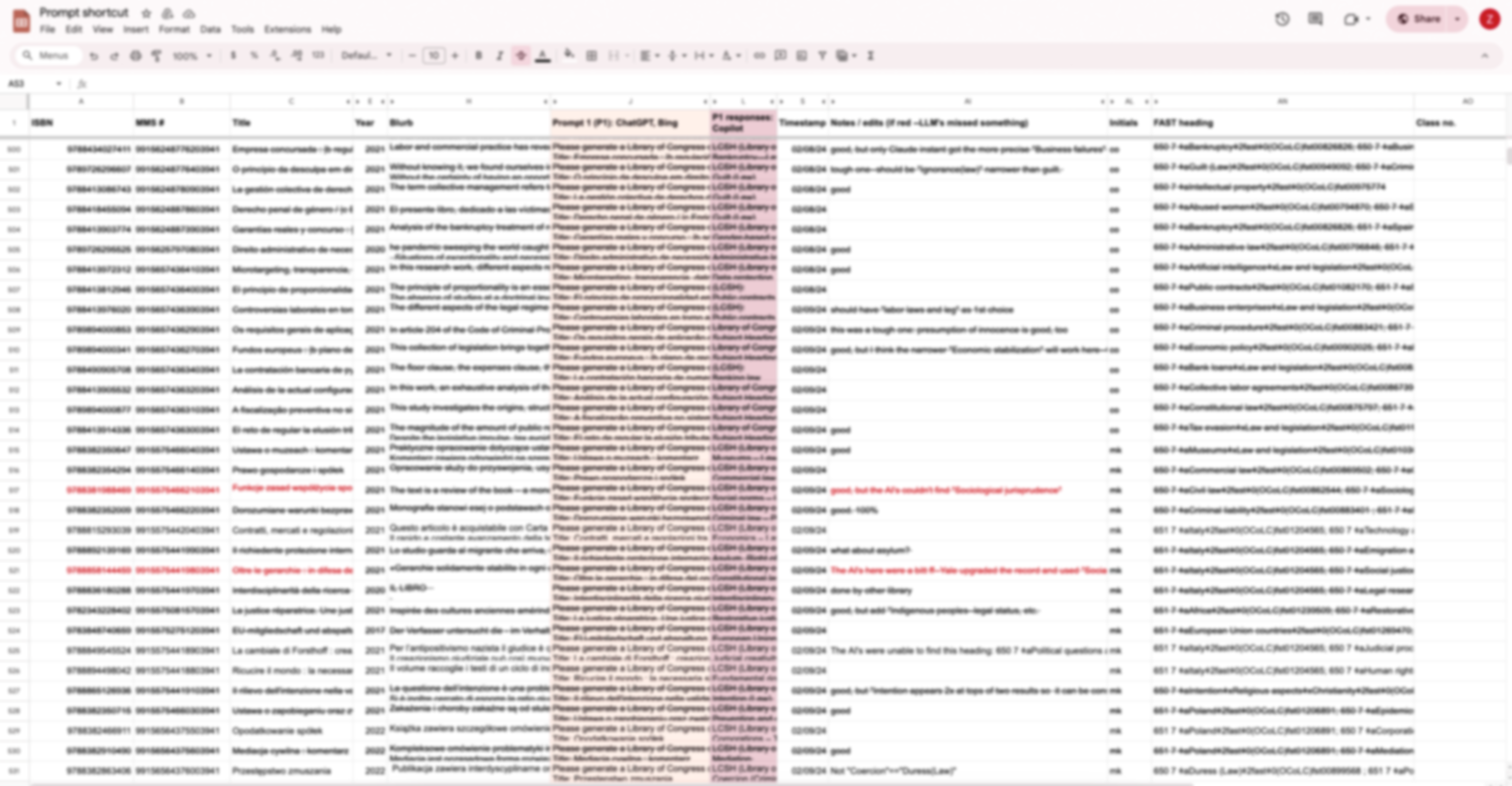
Title & Summary
Book titles and summary cover the gist of the content. Library
Catalogers assign subject headings by reading those two
fields.
Subject Headings
Subject headings are the handles linking a book and the
knowledge network. Accurate subject headings ensure readers
can easily access the information they seek and connect
related content. When books are acquired by Harvard Library,
catalogers assign headings based on the book's title and
summary.
ISBN
ISBN is book's unique identifier.
research
Use Large Language Models to Generate Subject Headings with Book Title and Summary
Assigning accurate book's subject headings is a crucial but time-consuming part of library cataloging. It requires in-depth knowledge of subject taxonomies and familiarity with the library's collections. However, the process is iterative in nature and does not require perfect accuracy initially. These characteristics make cataloging amenable to AI assistance.
Phase One
Vanilla LLM
Only utilize LLMs for generating subject heading response
Phase Two
End-to-End AI Agent
Take care of the whole workflow with the book title and
blurb search as data preparation to post processing AI
responses into correct FAST heading terms and format
Phase Three
Interactive UX
The AI cataloger is designed to reveals results
at each step, permits transparency, manual
modifications, and evaluation measurement, and facilitates
better human-AI interaction.
problem
Learn the Limitation from Early Experiment
Vanilla LLMs
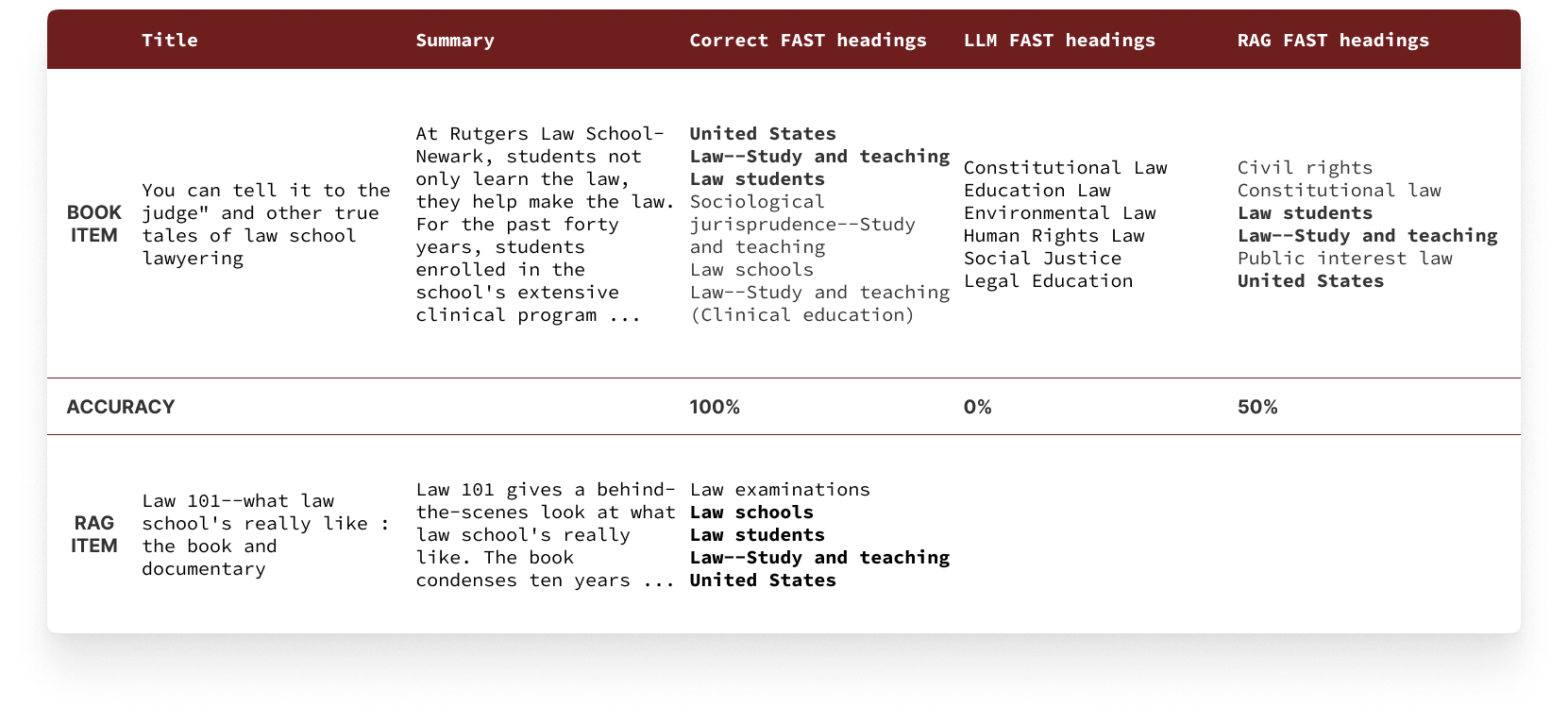
An early experiment using ChatGPT (GPT-3.5) to generate headings
from book titles and summaries achieved 70% accuracy.
Significantly, it took catalogers only half as long on
average to process items with AI-generated headings compared to
doing it from scratch. This proved the viability of using AI to
aid the workflow.
However, further testing uncovered some limitations.
Headings varied between model runs, undermining reliability. The
model also struggled with authority distinction, such as between
Library of Congress Subject Headings (LCSH) and Faceted
Application of Subject Terminology (FAST). Additionally, the
barebones AI responses required substantial post-processing by
catalogers.
Vanilla LLM Workflow
Tested on 300+ book items, Vanilla LLM achieves 70% of the accuracy and saves half of the time.
Solutions - 1
Overlaps among Multiple LLM Responses
Challenge
1. Lack of Stability and Hallucinations
The generated subject headings can vary between different runs with a 70% similarities between each runs. This randomness undermines the reliability needed for consistent cataloging practices. Meanwhile, LLMs can sometimes generate incorrect or overconfident information, often referred to as "hallucinations."
Solution
1.1 Multiple LLMs:
We ran prompts through multiple Foundation Models to generate subject headings and assigned higher weights in the result with overlap headings to coutner randomness.
1.2 Cross-referencing with SearchFAST API:
With LLM responses, we cross-referenced these outputs with established FAST heading databse through SearchFAST API to filter out errors.
3 AI bots
192
out of 214 have overlapped options among 3 bots
89.7% Overlap ratio
121.4% accuracy compared to a single AI bot response.
9 minutes cross-referencing SearchFast API for 214 items

Solutions - 2
Retrieval Augumented Generation (RAG) with library data and Prompt Engineering
Challenge
2. Difficulty Distinguishing Types of Subject Headings
Subject headings have different authorities, like Library of Congress Subject Headings (LCSH) and Faceted Application of Subject Terminology (FAST), etc. With LLM trained on both data, it often misuse lcsh subject heading in its response.
Solutions
2.1 Prompt Engineering
To improve the subject headings, we engineer the prompt to describe the difference of FAST headings in details to help LLMs generate the correct content and ideal format.
2.2 Retrieval Augumented Generation (RAG) with library data
Using the book items in the library database, we established our dataset to retrieve relevant books as references for generating subject headings for new books. The retrieved relevant book is added as part of the prompt for LLMs to reference.
Human-AI Interaction
AI Agent - Reveal Steps and Allow User Interaction
Challenge
3. Human-AI Interaction
The LLM response is basic and requires significant effort from librarians to find book titles and summaries online and post-process the AI response for accuracy and proper formatting. To enhance the workflow, we aim for the application to function more like an agent, handling the entire task with opportunities for human interaction and intervention.
Solution
3.1 AI Agent - with an end-to-end workflow
Given the limitations of the vanilla LLM query, we have developed an end-to-end workflow extending beyond a simple AI bot query, including data input preparation, to post-procession the AI-Bot responses.
3.2 UX Design - reveal Steps and Allow User Interaction
The AI cataloger is designed to reveals results at each step, permits manual modifications, and facilitates better human-AI interaction through its design. By creating a transparent workflow, we can also evaluate performance by isolating the results at each step.

Title Input — Customizable title input, which can be found on vendor websites or within the Alma library data system.
Summary Input — Customizable summary input, which can be filled in with the book blurb from vendor websites.
Prompt Input — Users can adjust the prompt as they test. However, we suggest sticking with a prompt and collecting results to analyze its performance. Once an ideal prompt is identified, it should be consistently used.
Response and FAST API Cross-Referencing — In each AI bot panel, users can expand to see the original response and the result after cross-referencing with the FAST API.
FAST API Interface — When users identify a potentially better FAST Heading related to an AI response, they can manually search using a panel. Instead of displaying only the top matching FAST Heading, we show the top three matches for users to choose from.
FAST Heading Final Adjustment and Export — Once a better heading is identified, it can be added to the next panel. Overlapping headings are displayed at the top, indicating a higher likelihood of accuracy. Single-occurrence headings are shown in a lower section. Users can customize the sequence and adjust the selections as needed.
Thoughts
GEN-AI to Application
Synthesize Information and Define Scope
With the release of ChatGPT, AI is expanding into professions beyond what we previously imagined. The integration of Gen-AI into library cataloging holds transformative potential for the industry. Developing an LLM for this purpose involves an iterative process, with book cataloger from different library editting, collaborating, and improving the headings continously. , leaving a relatively high error toleration for book classification. Compared to library cataloger using their knowledge and subjective assessment, the AI cataloger is more consistant in this manner and can sustain the process.
AI bot to AI Agent
With the proof of concept of using Gen-AI to assist in subject
heading generation, building it into an application is a
significant leap forward. One challenge is designing the user
experience: we aim to provide an automated system that still
allows users to engage with the model and its details.
The AI Cataloger assists in the initial stage of the
task, reducing some of the manual, tedious parts. However,
nuances and details are hard to capture. I initiated some
observations with experienced library catalogers to improve the
algorithm, such as separating the algorthm processing topic and
geographical FAST headings. In the short run, we still need
professionals to help fine-tune the system.

